Conducting a large-scale educational research study is a complex and demanding task. While much of the spotlight often falls on findings and policy recommendations, what remains less visible, but equally crucial, is behind-the-scenes work, particularly data management. In contexts like Pakistan, where the educational research infrastructure is still developing and there is a visible push towards evidence-driven decisions, data management processes need to be standardised to ensure the quality and credibility of results. In every research project, data management should begin even before data collection starts and continue through to the final stage of analysis.
This blog draws on our experience of managing data for large-scale studies, funded by DARE-RC, focusing on student learning outcomes and classroom practices along with other aspects in various types of schools across the diverse regions of Pakistan. In each study, there were 3500+ students and 400+ teachers. The data were gathered through achievement tests, classroom observations, survey questionnaire and interviews. Operating at this scale meant confronting multiple challenges including logistical, linguistic, and technological. We discuss how the core team developed and implemented standardised data management protocols and navigated challenges of scale, standardisation, and alignment. In other words, we present an insider’s look at how we organised, coded, marked, entered, and cleaned quantitative data and transcribed and coded qualitative data to make sense of large-scale data.
Our aim is not only to document procedure, but to provoke critical reflection on the labour and care required to produce trustworthy educational evidence in the Global South. We hope this will be useful for future researchers to manage research projects.
Ax Expert’s Advice on Rigorous Data Management
The process involved four key steps for data management considering the nature of nationwide studies. These include: 1) organising datasets using encryption, 2) marking student assessments based on pre-defined answer keys, 3) entering and cleaning data using standardised SPSS templates, and 4) transcribing and coding interview data. Dedicated central teams for each study were oriented on protocols and followed a comprehensive set of procedures at each stage of data management.
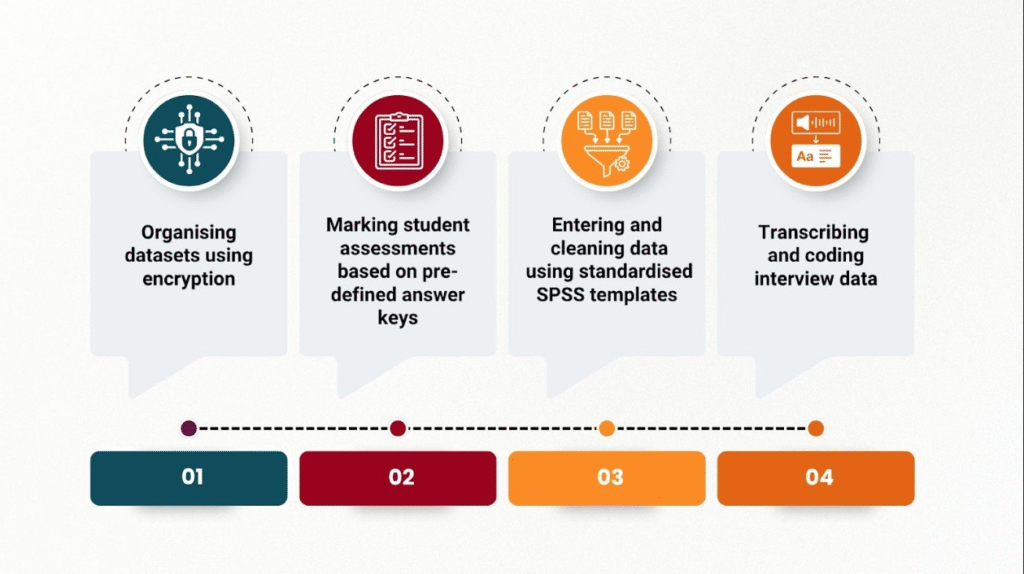
Step 1: Data Organisation with Encryption
Our data management journey began immediately after completing fieldwork in the first region. Each student’s learning assessments (Science and Mathematics Achievement Tests), demographic sheet, and survey questionnaires were bundled together and assigned a unique encryption code. The same approach was followed for each teacher’s data, including teacher questionnaires and classroom observation rubrics. This “encryption” was not digital encryption in a cybersecurity sense, but rather a structured system of alphanumeric codes assigned manually to ensure anonymity and traceability.
An example of a student data code is BQG1, where B represents Balochistan, Q stands for Quetta, G denotes government school, and 1 is a unique sequential number. Similarly, an example of a teacher data code is BQGT1, where B represents Balochistan, Q stands for Quetta, G denotes government school, T indicates teacher, and 1 is the unique sequential number.
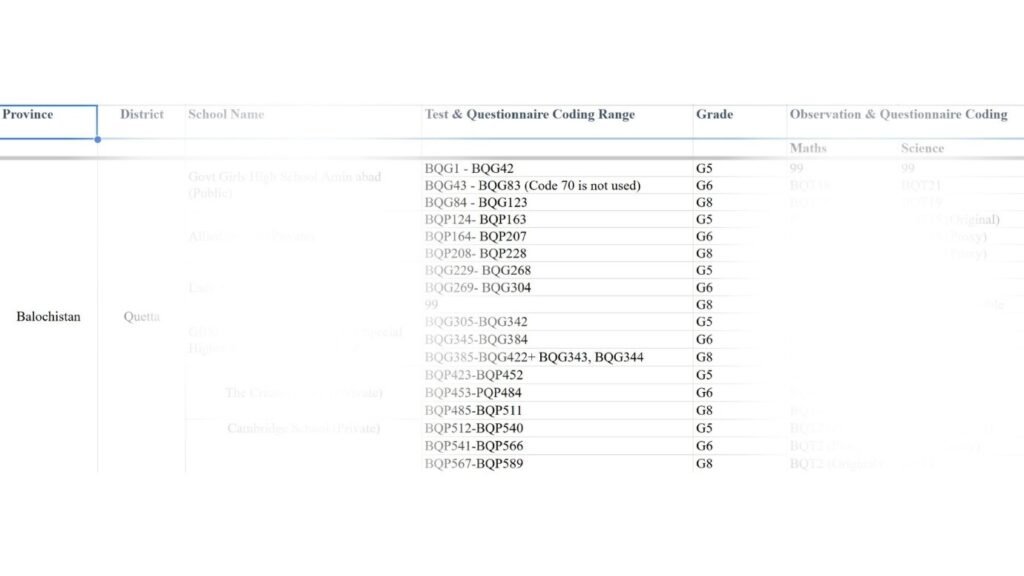
These individual-level documents were then organised into labelled ‘school packs’ to enable easy access and quick referencing. To ensure that teacher data could be linked with student outcomes, we developed an Excel-based tracking sheet, aligning each teacher’s code with the codes assigned to their students, as presented in the image below. This system allowed us to synchronise datasets efficiently and prepare them for merging at later stages.
Image displaying data organisation on an Excel sheet
Step 2: Marking Student Assessments with Reliability
Assessing students’ performance in achievement tests, particularly constructed response questions, requires careful attention to consistency and fairness. To standardise the marking process, we developed detailed answer keys and trained all research assistants involved in assessment scoring. Additionally, we ensured that assessors had subject-matter knowledge as well as language proficiency.
Initial assessment was carried out collaboratively for a subset of schools, allowing the team to calibrate their approach and resolve any discrepancies. Monitoring by the core team was a consistent feature of the marking process in order to maintain quality. We also assessed inter-marker reliability, which refers to the consistency with which different evaluators score the same test responses. To ensure fairness and accuracy, we established a threshold of at least 80% agreement between markers before proceeding to mark test papers independently. This reliability did not emerge spontaneously; it was sustained through regular audits and mandatory random rechecking of papers before data entry.
Step 3: Structured Data Entry and Cleaning
Separate databases for student and teacher data were created using SPSS (v27). A shared SPSS template with a fixed variable structure was developed to maintain consistency. This structure specified uniform variable names, labels, and coding schemes (e.g., for student demographics, questionnaire, test, teacher characteristics, and classroom practices), ensuring that data from different sources could be entered and analysed in a standardised way. Centrally hired research assistants, trained by the core team, were assigned grade-specific responsibilities for student data entry. Teacher data, being more manageable, was entered by a single person to ensure uniformity and reduce variability.
We enforced a strict protocol prohibiting any changes to the variable structure in the SPSS template without prior approval from the core team. This protocol ensured consistency in the datasets, which in turn made it easier to merge data entered across different grade levels. Data entry was complemented with routine random spot checks to immediately identify and correct any errors.
Before data analysis, comprehensive data cleaning for the entire data was carried out soon after the completion of the data entry process of both sets of data by running frequencies of each variable and rectifying emerging errors. Since, we had multiple data files, and it is essential to merge them together. Both the data sets (i.e., students’ assessment data and classroom observation data) were merged in a single file in order to make them ready for statistical analysis. After merging the data sets, the complete data set was double-checked in order to ensure that the observation data of teachers are placed appropriately with respective students’ test scores.
Step 4: Managing and Analysing Qualitative Data
The qualitative component of one of the studies explored how teachers conceptualise and implement participatory teaching strategies. With informed consent, all twenty-one interviews, ranging from 45 to 60 minutes, were audio-recorded and transcribed in their original languages to preserve contextual accuracy. Selected quotations were later translated into English for use in reporting. The analysis involved a multi-phase process, including, 1) open coding to identify meaningful segments; 2) categorisation of similar codes; and 3) theme development to synthesise emerging patterns.Two research assistants were trained and tasked with independently coding each transcript. Their individual codebooks and coded transcripts were reviewed by a third senior research assistant to ensure accuracy and consistency. This triangulated approach yielded an inter-coder reliability score of 80%, considered acceptable in qualitative research. The lead researcher from core team subsequently grouped open codes into categories and developed themes, which were used in the final analysis and reporting.
Good Data for Enhanced Credibility
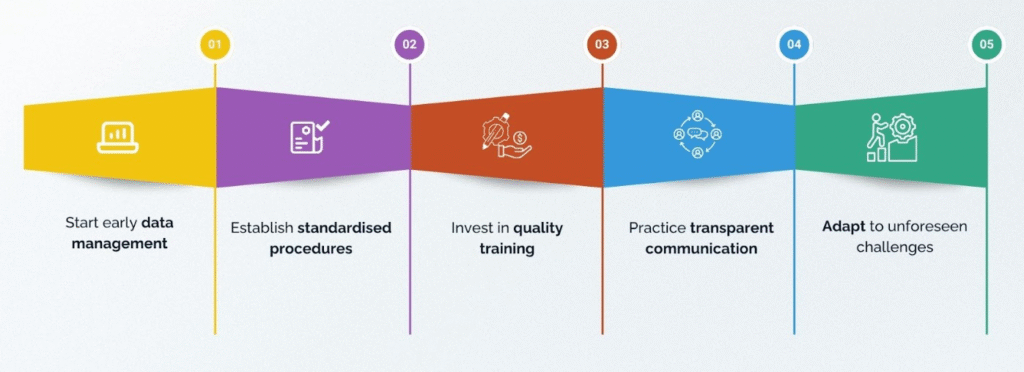
Our experience offers several key lessons for researchers managing large-scale datasets.
First, data management should begin early, ideally during the planning phase, rather than after data collection has concluded. Second, establishing standardised procedures, such as using uniform templates and shared coding systems, reduces errors and improves consistency across teams. Third, investing in training is critical, as research assistants require structured guidance and oversight to maintain data quality. Fourth, transparent communication within the team fosters collaboration and supports data integrity throughout the process. Finally, while adherence to protocols is essential, teams must remain flexible and responsive to unforeseen challenges during data management.
In a nutshell, data management may not be the most visible part of research, but it is undoubtedly one of the most essential. In large-scale studies, where the risk of error is amplified, a careful, transparent, and collaborative approach to handling data can significantly enhance the quality and credibility of research findings. By prioritising robust data management practices, we not only strengthen the integrity of our evidence but also uphold the standards of responsible and ethical research.
Authors: Aisha Naz Ansari (Research Specialist, Aga Khan University, Institute for Educational Development (AKU-IED), Sohail Ahmad (PhD Candidate, University of Cambridge), Dr Sadia Muzaffar Bhutta (Associate Professor at AKU-IED), and Dr Sajid Ali (Professor at AKU-IED)
Editor and Quality Assurance: Dr Sahar Shah (Senior Research Manager, DARE-RC)
Copy-Editor: Maryam Beg Mirza (Assistant Consultant, Education at OPM)
Design: Sparkom Media
The views expressed in this blog are that of the authors and do not reflect the views of DARE-RC, the FCDO, and implementing partners